

HTTP 302 vs 303, the debugging nightmare
Decoding HTTP 302 and 303 Redirects: Unraveling the Web's Redirect Mysteries



you may be very well aware that there are many HTTP status codes, which convey meaning and miscellaneous context to the response returned to the client from the server.
variety of options and their cryptic academic descriptions might make you question differences and may drive you to use one for all cases, where unfortunately it might cause more headaches than convenience.
One such pair is 302 and 303. Being 3xx, it is obvious response is a redirect. But, did you know a single increment in the last digit changes the behavior drastically? The above leads you to the MDN docs. The sentence of interest is...

302 should not alter the Method or Body to a new
Location303 will issue a new
GET, see for yourself
So, what? There are pretty annoying debugging and critical error bugs that might come when interchanging the codes without thinking twice. First, let's see it in action. Shall we?
See for yourself.
all code can be retrieved from this GitHub Gist
The scenario of interest is redirection. So, we will set up an endpoint, that will request a resource to another endpoint; the requested endpoint will then redirect to the final endpoint which will return another response. Feeling Dizzy 😵 or lost 😖? Here is the flow diagram ⬇️ with numeric indicating flow order.
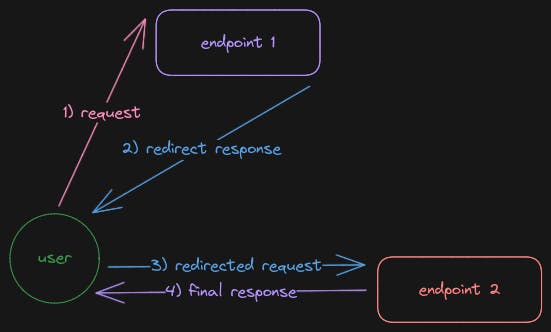
The concern is on status code of 2) redirect response and request method of 3) redirected request.
Tech stack
Since this is just a demo, I will use built-in http server of Bunjs and htmx.js to issue different HTTP methods to indicate potential real-world scenarios.
Setting up the server
In case I delete the gist in the future, here is the entire server code.
const server = Bun.serve({
port: 3000,
fetch(req) {
const url = new URL(req.url);
switch (url.pathname) {
case "/":
console.log("root access");
return new Response(Bun.file("./index.html"))
case "/302":
console.log("302 endpoint");
// 302 is the default behavior of `redirect`
return Response.redirect("/end");
case "/303":
console.log("303 endpoint");
return Response.redirect("/end", 303);
case "/end":
return new Response(`endpoint hit with HTTP method ${req.method}`);
default:
return new Response("404")
}
},
});
console.log(`Listening on http://localhost:${server.port} ...`);
And, here is the index file that will be served and have the button to issue requests and demonstrate the effect.
<html>
<head>
<title>302 and 303 Diff Demo</title>
</head>
<body>
<h1>SUTBLE Difference between Redirect 302 and 303</h1>
<button hx-delete="/302" hx-target="next #target" hx-swap="innerHTML" type="button">
issue request to 302
</button>
<button hx-delete="/303" hx-target="next #target" hx-swap="innerHTML" type="button">
issue request to 303
</button>
<div id="target" style="margin-top: 10px;">
</div>
<script src="https://unpkg.com/htmx.org@1.9.9"></script>
</body>
</html>
for the above code,
index.htmlandindex.tsshould be on the same directory level

you may run sever with hot argument to allow hot reloading while tinkering.
bun --hot run index.ts
The showdown
When clicking on the 302, a text will appear below the buttons. Read that. Should be like...

Now, click on the other one.

Do you notice any difference? In case you do not, the methods are different. Let's take a look at the index.html again, shall we?
Buttons to request the resource are as follows(I cleared unwanted attributes for brevity)...
<button hx-delete="/302" type="button">
issue request to 302
</button>
<button hx-delete="/303" type="button">
issue request to 303
</button>
The hx-delete is from htmx, which will request a DELETE HTTP Request to /302 or /303 endpoints depending on the button the user clicked. Here both of these endpoints are examples for the endpoint 1 in the diagram given earlier.
Let's examine the server code for both of these endpoints.
case "/302":
console.log("302 endpoint");
// 302 is the default behavior of `redirect`
return Response.redirect("/end");
case "/303":
console.log("303 endpoint");
return Response.redirect("/end", 303);
As you can understand, we log the request to std-out and then return a redirect response. Each returns with a different status code but the same Location the /end. The /end returns a response with a string indicating the method of the request.
case "/end":
return new Response(`endpoint hit with HTTP method ${req.method}`);
htmx will then swap the returned value with the innerHTML of the div with the id target. As I said earlier the http method is different! this is by design and what the standard also drafts out. So what's the catch?
Wolf in sheep cloth

I wanted to write about this as I have stumbled upon this myself and have successfully lived 2 hours of nightmare debugging my side project. This is how it all happened...
I had a
PUThandling handler at an endpointafter a successful update, I redirect the request to the details view
details view is a resource tied to
GETmethod
But to my surprise, I was getting 403 Method Not Allowed response back. 😬. URL was right but the http method was wrong. I didn't know why the browser was issuing PUT method to redirect URL.
I tested this with some sites but for those browser-issued GET request. 🤷♂️. After doing all sorts of debugging and resorted to reverse engineering. I wanted what the differences are between my requests/responses and this particular site's requests/responses. I diffed and to my surprise, apart from dates, content length and such dynamic headers, the HTTP message was different along with the code.
I MDN-d the code and turns out the default behavior of the redirect is to have a 302 status code, which means found in another place! So the browser redirected the request body and all with only the URL changed. 🤦♂️
My tragedy aside; I wanted to stress out that before debugging in, make sure what the framework does by default so you know what's happening. A similar case came to me a few years back.
I wanted to compile surrealdb inside a Tauri app. But the compilation failed and it turns out devs cross-compiled it. So, I dug deeper and found an interesting mechanism of how GNU-utils ruined my day. You may read more here, in this blog which got me third prize in the Hashnode debugathon 🤗
Wrap up
That's all I wanted to say for now. See you on another one, till then it's meTheBE, signing off!