



For the first major version of kopf(v1.0.0) I am planning to have simple feature set to just get it running. Following list are non-exhaustive and may change as I please 😉
Functional Requirements
- Save/Retrieve Data from CSVs
- Understand Basic SQL
- Communicate via Sockets
- Selective Indexing
- Table Partitioning
- Don't abandon the project in the middle 😂 when interest is lost
Non Functional Requirements
- Optimal Latency
- Less IOps
- Small memory footprint
- Scheduled Backup (🤞)
Building the Stack
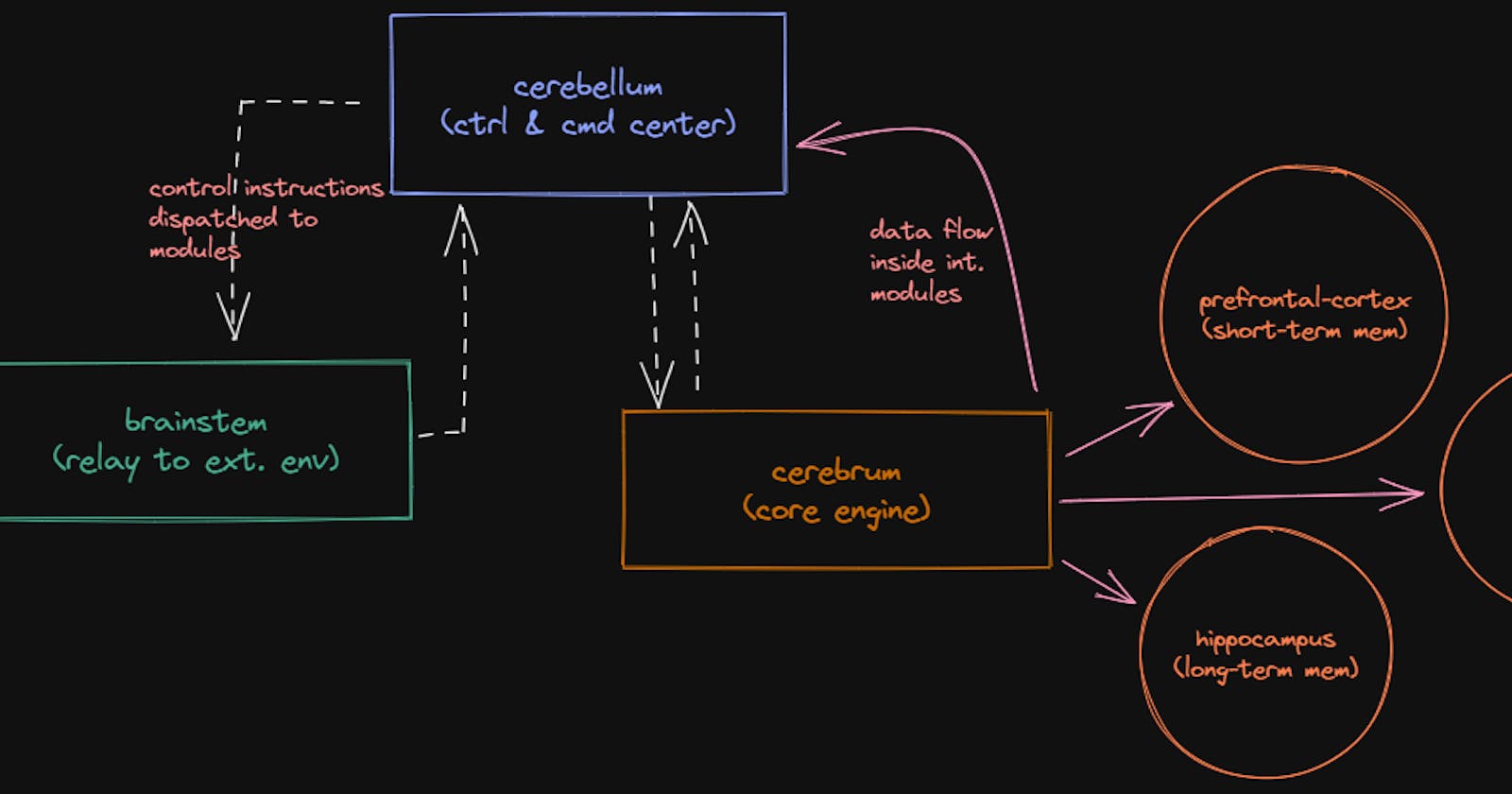
We will start from inside out. First we'll build the cerebrum to have
persistant datastorage then cerebellum for command execution and have the
cerebrum understand the issued SQL. At last, we will tie up with
brainstem be able to communicate with external env. using sockets.
So we need to:-
- IO with CSV
- Have a worker-master model with
cerebrum-cerebellum - Socket Programming
- Have in-memory B+Tree of CSV contents
- An algorithm for sorting
- Radix if row-count > 10000
- Insertion if row-count < 1000
- Merge else
Some Design Decisions
- First of all, I will implement a prototype in python, then try to implement it in rust/C.
- I am a big fan of binaries, so Queries will be encoded to binary and interpreted as is!
- I will add more As I progress!
Deep Dive
The cerebrum
Biologists divide memory-functionality of the brain into 3 parts. Name...
- Encode/Decode: Understand and realize what we learn and remember
- Store: Persist what we learned/remember for short-&-long --term usage
- Retrieve: Consume back what we learned/memorized
So, I will have my way at it as aforementioned! My cerebrum will follow
these steps.
- It will have a module to
en/de-codethe SQL issued by thecrebellum. - A
short-termin-memory caches and indexes for quick recall ops - Persisted in-disk CSVs for
long-termmemory - And a way to decide between whether to retrieve from
longorshortmemory during execution of queries
Employed Datastructures
For in-disk, we will mimic Apache kafka's SSTables. Any write will only be
appended without any seek. But, instead of conventional deltas, we will write
result of the query on the existing data. Then have a worker scheduled to clean
previous corresponding rows. I will coherce with the saying...
What is Done, Is Done.
... i.e. no rollback once the transaction is committed. No fallback. No f*@k by default. But admin/engineer can opt in to trade-off space and extra check to eliminate old-duplicate results for high availability and fallback backups.
For in-memory, I will employ conventional B+Tree ofz.
The cerebellum
This is captain of the ship. I want to use pub/sub models with 1-producer & many-consumer, but let's see, what future holds. In my mind, for the first rc, just wanna schedule function calls in a queue then be done about it 😂.
cerebellum will be the glue of both brainstem and the cerebrum. So, this
will be my high-hot-spot & single-point of failure if anything should go south.
The brainstem
API to the external systems. This module will be responsible only for getting
the request from outside by sockets and then strip off unneccessary stuff
from the payload and only send query and params to the cerebellum. Take
result from cerebellum and then cooks the response and respond via
pre-established awaiting socket or new if client wants asynchronous ops.
Payload detection in async communication
One challenge that I foresee is confusion when results donot arrive in order as issued during async communication. So, each payload(request) from externals will have a unique id in following format: - e.g. 1-1 for a client id with 1 and payload id of 1 OR 2-23 as such. Note, we will impose that payload id should start from 0 or 1 to have small payload size and be sequentially increased.
why not conventional cuid or uuid?
Obviously the size. uuid is 16 bytes long. But, an integer is just 8 bytes litterally I can write logs in any order and in agrregation I can just sort them with payload_id.
Have a very good luck sorting with uuid eventhough uuid generation is seq.
In uuid case, I will have to use another operation or store them in order for audit logs and WAL.
I know, this is vague, I might change. If I am wrong, please do comment and teach me using comments section