




A regular expression (here on, I will refer to as regex) is not scary as the meme states. It just needs a little patience and knowledge of the state diagram.
Regex is just State Diagram!
Only sounds fancy, but in a nutshell, it is just a primal flowchart.

from community.coda.io
Assume, you are to analyze users and their location. Since now a day everyone is anxious about their privacy they tend to mask their location. Your conclusion might be off and bring millions of $ lost. 😳. One way to do it is to ask phone number for 2FA and then analyze the phone number 😜. Just state it vaguely in the T&C or Privacy Policy.
So, phone numbers then, yeah, they have a system and encode location data. But a bump is that you never enforced a pattern to the end-user. So, when you try to look at the head, you see this,
000-02-2344
000 02 2343
001.23.2342
023-02-2344
Imagine you have a million users or so. WTF! So, you sanitize at pre-processing state. How?
user_pns = [user.phone_number for user in Users()]
pns_sanitized = []
for pn in user_pns:
if '-' in pn:
# sanitize how ever you want
pns_sanitized.append(pn.replace('-', ''))
elif '.' in pn:
pass
else:
pass
But, what if someone inputs a phone number as 002-02.2344. They must have been in hurry, so they mixed up delimiters. Your script will leave . out and you have inconsistent data to model. Heck even what if some lunatic used * or had (...) to indicate the beginning? Are going to write if, elifs for all of that?
Do you realize that the fact each branching will penalize the performance write? If not search CPU Shadow Realm Exploitations. What should you do? Call parser’s 911, The Regex.
No matter how end-user input, the number will always be xxx xx xxxx or some other way depending on your users’ locality which you can query from where 2FA codes be sent (Cuz LTE or any cellular protocols require specific country data). Let’s consider the scenario of the pattern I mentioned above.
The pattern xxx xx xxxx can be represented as \D*\d{3}\D*\d{2}\D*\d{4}. Gibberish? Let me tell you the lexemes or the grammar of Regex.

for more, check the link below 👇
Regex Cheat Sheet: A Quick Guide to Regular Expressions in Python
So \D*\d{3}\D*\d{2}\D*\d{4} becomes: -
Interest start can ** ,* start with non-numeric,
\Dthen 3,
{3}, numeric\d, followthen optional
*non-numeric,\Dthen after 2,
{2}numeric,\dfollowed by optional
*non-numericthen 4 numeric.
OR, you can think of the regex as a map of how a finger should move across a piece of string, a state diagram.
see, I told you 😘
Now you can like ❤ the button is at the bottom of the screen 😎.
Each logical piece represents each state.
Special characters move the finger (
$ ^or just EOL), start or stop signals,groups are saved to memory, output to tape,
characters indicate progresses of the finger like, move finger if and only if under the finger we have alpha-numeric (
\w), creating conditionals,length/numbers represent how many times the finger should sense a given character, like 4 times
{4}or should it be 0. Creating loops and sequences;If by any chance the finger can’t transition to the next state, then the machine terminates and starts from the beginning on another window of the specimen.
See, it is just a state machine in disguise. Once you get this fundamental right, you are off to 🚀.
The Tip to compile it.
Just take an example and put your finger on the leftmost side of the specimen.
Ask yourself what you should do to advance to the next character. Should you encounter a numeric or alpha or whitespace.
Do it till you find yourself at the right-most character of your specimen.
Now just like you factorize an integer, factorize your state transitions. E.g., if we have 12 then we can write it as
3 x 2 x 2, that one becomes,3 x 2^2. So, we have a 3 and 2 appears2times.
Now, map it as a state diagram by head or if it is complex, take a piece of paper and just sketch it. No need to follow the symbology or conventions. It just should express what your mind says. Heck even, you can use Flow Chart. Because any state-machine or Turing Machine can be expressed via a Flow-Chart.
Let’s look at an example. Say, we need to extract the names of people from phone book entries along with prefixes. Step 1 is to get an example.
Mas. Birnadin Erick
Put your finger in the leftmost character,
M.Ask what we should do to progress to the right. We should encounter an alphabet.
Then again, an alphabet and so.
A period,
.;Now a whitespace
_,Now an alphabet, but in Uppercase.
…
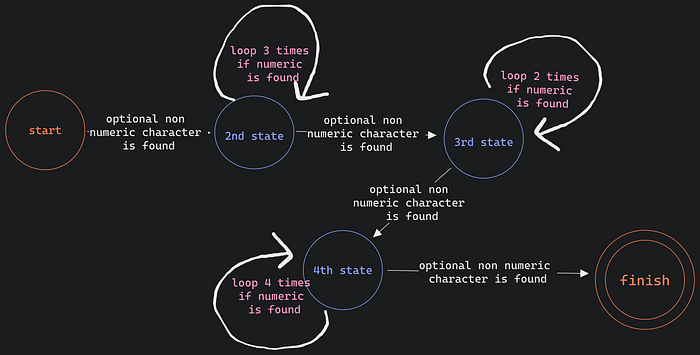
If in the diagram, then traces would be…

from the start to 2nd state

from 2nd to 3rd

from 3rd to nth
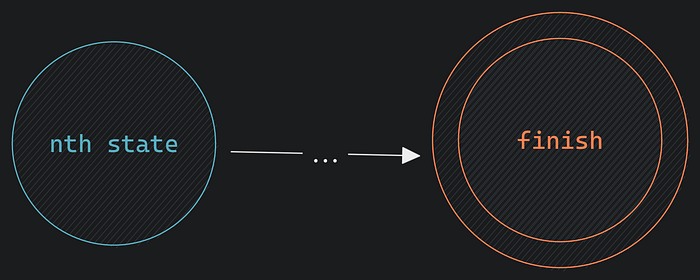
nth to finish.
Are we done? no there is another possible variant!
Ms. Jane Doe
The difference would be from 2nd to 3rd we have to scan an s.

2nd to 3rd state transition changes
Everything else stays the same, hence a common factor, have we. Done? Nope.
Mr. John Doe
This time, 2nd to 3rd trigger is r.
So, 2nd to 3rd have more than one transition.
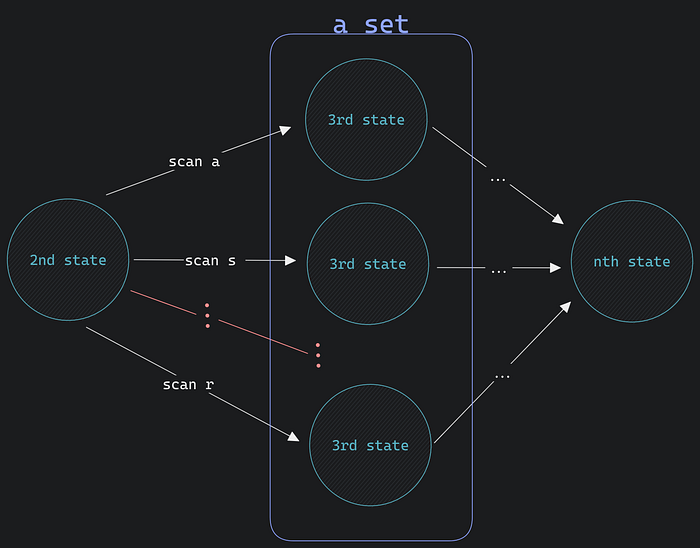
different paths machine can deviate.
And, in between an nth and (n+1)th state may share the same trigger but multiple times. E.g., along irnadin in Birnadin, i and r are the same trigger but have multiple points of presence.

first pass;
👆 can be simplified as 👇

simplified on 2nd pass.
So, as a result, our state diagram becomes like 👇
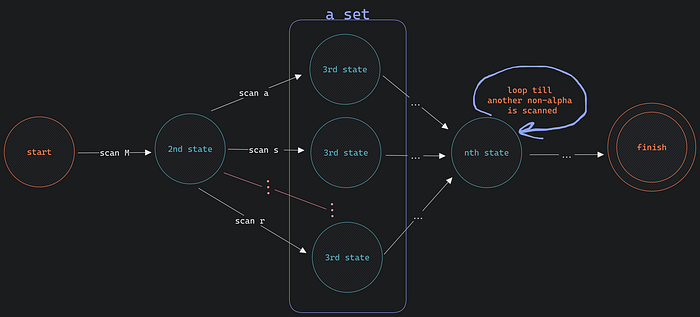
click to zoom and analyze 🔍
Compilation
gives: M
this gives: M[asr]
Then the . gives us M[asr]\W* , there could be presence or absence;
The whitespace gives us, M[asr]\W*\s*, there could be more than 1 space due to input errors;
Then an Uppercase: M[asr]\W*\s*[A-Z], you could actually say \w instead of A-Z if you want;
we end up with: M[asr]\W*\s*[A-Z]\w*
The same goes, thus we end up with 👇
M[asr]\W*\s*[A-Z]\w*\s*[A-Z]?\w*
# last [A-Z]?\w* means there could be last name or not
# if you know for sure, prefix is delimitted by period
M[asr]\.*\s*[A-Z]\w*\s*[A-Z]?\w*
Do you feel how easy it is? Told you Regular Expression is just State Diagram in disguise 🐑.
Epilogue
I hope I shed somewhat light on regex using how I understand it. If you disagree or have an example that contradicts, please let me know in the comments, would love to be corrected beforehand.
Another post is coming soon using Regex in Python, Rust and JavaScript.
If you are intrigued or interested in this kind of stuff, make sure you follow me on Twitter.
Till then, it’s me the BE, signing off 👋
Cover background by Steve Johnson.