

Why Numbers Don't Align: A Deeper Dive into Integration and Design
Don't judge a book by its cover! 3.9GHz 80 cores loses against 3.7GHz 40 cores.




Photo by Joshua Hoehne on Unsplash
Yes, you read the title right. This is why I am always skeptical about spec sheets rather than trust benchmarks as the latter is what it is.
TLDR;
It was a better hardware-software match that gave Power S1022 the win
Apple was right in making its Silicon M series ARM(RISC) chips
Vendor-Lock is not a bad thing after all
The opinions I express are entirely my own and may not necessarily represent the views or stances of any organization or entity I am associated and/or affiliated with. With that being said, I have pointed out places where I believe but not necessarily truly (accurately)tested, and based on information I found public which can't be proven correct.
Prologue
LinkedIn recently suggested this post. It links to this paper, a comparison by IBM on performance and cost (for 3 years) of its Power server and an alternative. Of course, the paper concludes IBM Power server is better, if not they wouldn't have published it in the first place 🤷.
But, on paper, the alternative sounds like a better solution (and so what I thought 🤦♂️). The exempt...
x86 Ice Lake Server (x86 Environment):
CPU: 2 sockets 3.9GHz 40 Cores
- Total Cores: 2 s x 40 c = 80 CPU cores
Architecture: amd64
Operating System: Red Hat OpenShift version 4.9.18
Application Server: WebSphere Liberty
Environment: x86 environment (not specified in paper)
Virtualization: KVM
...some are my assumptions. The paper does not specify which CPU in particular, but Ice Lake has 40 cores as an upper bound, so I assumed that is what they are talking about. The protagonist is...
Power S1022 Server (IBM Power Environment):
Manufacturer: IBM
Model: Power S1022 (9105-22A)
CPU: 2 sockets 3.7GHz 20 Cores
- Total Cores: 2 s x 20 c = 40 CPU cores
Architecture: PowerISA (RISC architecture)
Operating System: Red Hat OpenShift version 4.9.18
Application Server: WebSphere Liberty
Environment: IBM Power environment
Virtualization: PowerVM
Both systems had 1TB of main memory, and from the Power server spec memory is most likely DDIMM DDR4, and so is Ice Lake specs. So I assume the memory was DDIMM DDR4 1TB for both subjects.
Benchmark was gained from JMeter evaluating 1.6K users' requests to DayTrader with a database server in a separate (physical) server. The Following Diagram indicates the setup, which is taken from an IBM-provided paper.
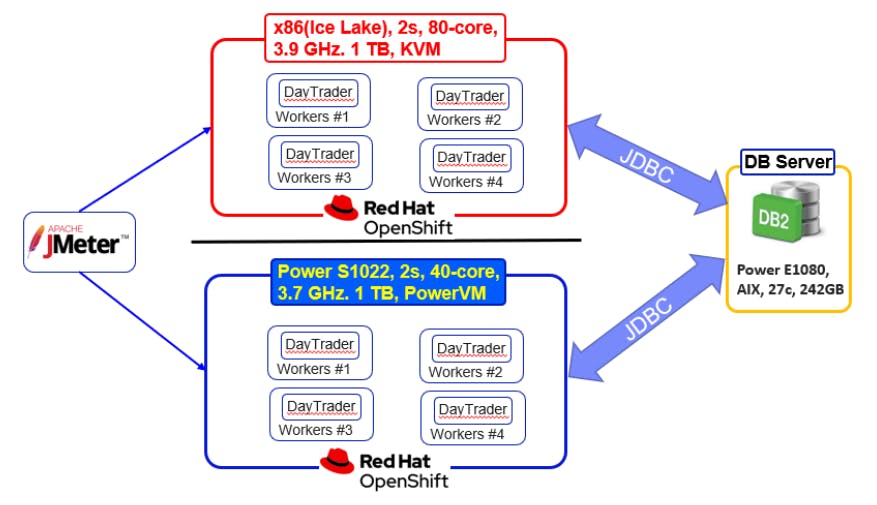
Let's do that one more time!
| Character | IBM Power Server | The alternative compared |
| Manufacturer | IBM | Not specified |
| Model | Power S1022 (9105-22A) | Not specified |
| CPU | IBM Power10 2 sockets 3.7GHz 20 Cores | Intel IceLake 2 sockets 3.9GHz 40 Cores |
| Total Cores | 40 CPU cores | 80 CPU cores |
| Architecture | PowerISA | amd64 |
| Operating System | Red Hat OpenShift version 4.9.18 | Red Hat OpenShift version 4.9.18 |
| Application Server | WebSphere Liberty | WebSphere Liberty |
| Environment | IBM Power environment | x86 environment (not specified) |
| Virtualization | PowerVM | KVM |
See? The alternative server seems like it can do more. A basic (not-so-accurate) math, 2 sockets x 40 cores x each 3.9GHz clock tick = 3.12E11 ticks per second; in microcode terms - 3.12E11 instructions per second, for Power it is 2.96E11.
Note, that it is
xxE11; so the difference of 1 will be 100,000,000,000!
So how come, 3.12E11 lost to 2.96E11 when running the same software? I was wondering the same, then it hit me.
CPU architecture is not the same.
CPUs/Virtualization are not the same either, but the amount of difference in clock speed is marginally large enough to eliminate any vendor-specific optimization, IMO. Let me know in the comments if you don't agree with me 😼.
RISC
Until the time I read this paper, I thought RISC was more of a slimmed-down version of CISC, which is used in mobile phones since mobile phones do not need as much power as macro PCs and other large-scale computers would require. But got the whole point wrong.
Most of the smartphones (and some macro PCs as well) use a specific chip flavor of RISC, ARM chips. But RISC is more than that.
RISC is Reduced Instruction Set Computer.
There you have it. RISC chips can do the same task as CISC but with fewer instructions. So, now it is the rationale why IBM Power had fewer cycles than IceLake but performed better! It is astonishing how (fairly)recent technology could beat legacy decades' worth of experience technology, amd64.
PowerISA vs amd64 deep dive
I am more intrigued. If this is better, why we are still using amd64? Compatibility? Sure, but RISC has been since 1986! Come with me to the land of assembly; the furthest I can get towards CPU without losing my mind 🤯.
Here is a simple rust squaring program.
fn sq(n: i32) -> i32 {
n * n
}
Assembly becomes for CISC(right) and RISC(left). In case you wanted to play with it here you go.

Above I filtered many other codes, this is the only relevant one. And compiled with
opt-level=3rustc argument.
CISC had to first move the parameter to eax register before it could execute imul. But in RISC, mulw can use a0 where the parameter is already placed. Same LLVM, yet a different binary! Thanks to same-sized parameters for all(in my knowledge) instructions in the RISC.
🔥 hot take
When you can assume aspects of the (hardware)environment without a dynamic nature, you can optimize the hell out of your software!
Let's do some realistic and relevant operations. Since the benchmark was on a trading app, why not implement a Simple Moving Average Crossover 🤷♂️
pub fn moving_average(data: &Vec<f64>, period: usize) -> Vec<f64> {
let mut sma_values = Vec::new();
for i in period..data.len() {
let sum: f64 = data[(i - period)..i].iter().sum();
sma_values.push(sum / period as f64);
}
sma_values
}
fn sma_crossover_strategy(data: &Vec<f64>, short_period: usize, long_period: usize) -> Vec<&str> {
let short_sma = moving_average(data, short_period);
let long_sma = moving_average(data, long_period);
let mut signals = Vec::new();
for i in (long_period - 1)..data.len() {
if short_sma[i] > long_sma[i] && short_sma[i - 1] <= long_sma[i - 1] {
signals.push("Buy");
} else if short_sma[i] < long_sma[i] && short_sma[i - 1] >= long_sma[i - 1] {
signals.push("Sell");
} else {
signals.push("");
}
}
signals
}
fn main() {
let price_data: Vec<f64> = vec![2.003, 0.5, 1.9];
let short_period = 50;
let long_period = 200;
let signals = sma_crossover_strategy(&price_data, short_period, long_period);
for signal in signals.iter() {
if !signal.is_empty() {
println!("{} now!", signal);
}
}
}
In case you have been wondering why rust, it is most straightforward to assembly next to C. But I am not comfortable with C. Yes, a skill issue. I admit 😔; And I have been seeing rust/assembly for years now.
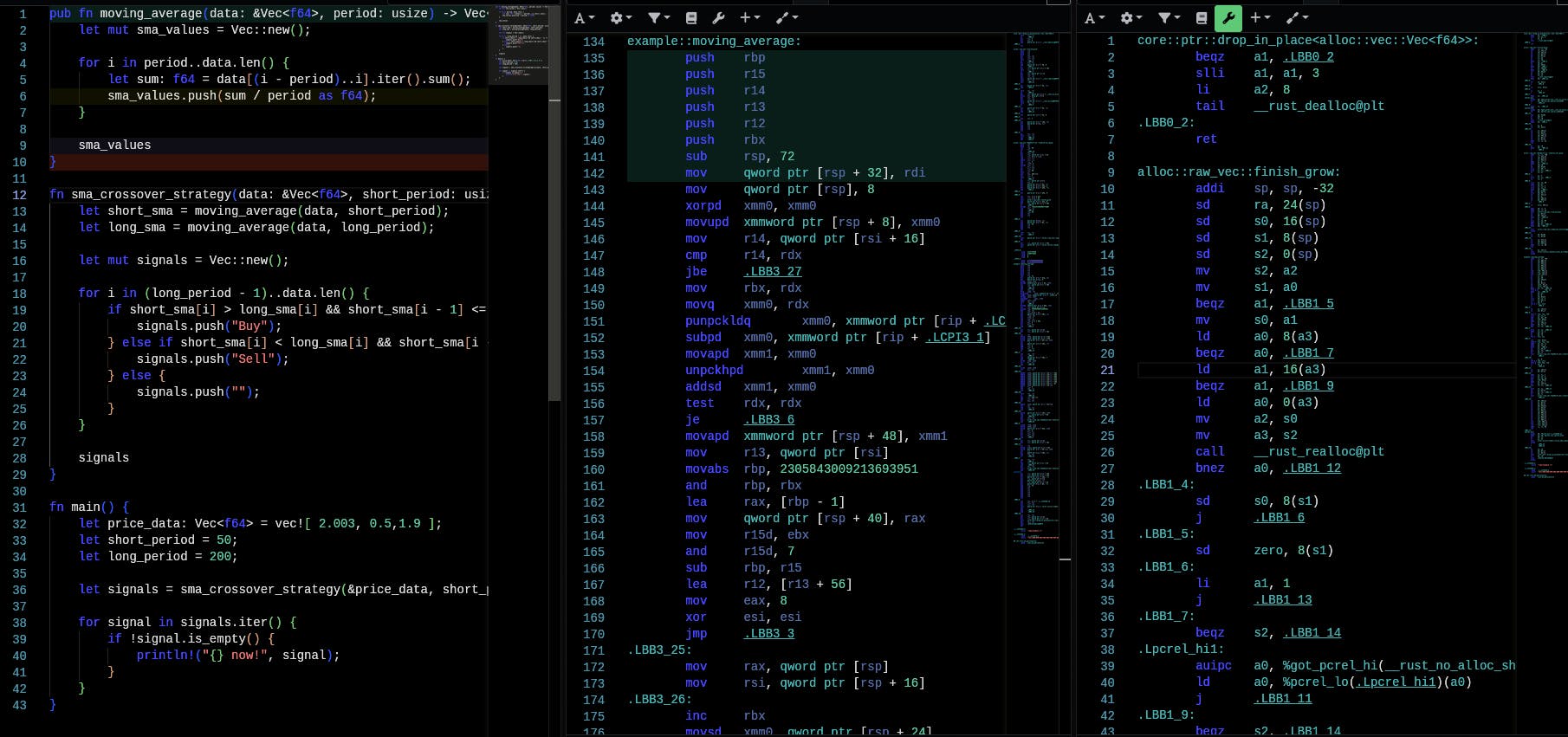
Quite a lot to unpack here. But the actual functions are less of LOC. moving_average in CISC (2nd column) starts at line 134 but the first 8 instructions are prologue. So not real magic. And in RISC (3rd column) starts at line 130. The same goes for the first few. They are funciton prologues.
Comparing LOC is not accurate, but for brevity I do!
What does this reduction in instructions mean? Less work to the CPU! Note, that assembly is not what the CPU runs. CPU runs the microcode generated from the assembly. Since microcodes are proprietary (the main business logic driving Intel vs AMD and such), I don't know how these translate, but RISC generates less and efficient micro-codes! That's my understanding.
CPU also has to fetch, decode and then execute an instruction. Some instructions might require address load (lea etc.) from the main memory which is very slow (~100 cycles). So better software? is that it?
CPU Fabrication
Embedding transistors and such, that is, constructing a CPU core is termed Fabrication here.
Our protagonist also has better hardware; especially...CPU. Though we now know Power10 architecture(the software, microcodes) is (mostly)efficient, from this wiki the Power10 fabrication is 7nm. But the IceLake is 10nm, although the difference is just ~3nm you can fit many more transistors which is (my guess is) why 40 cores lead the 80 cores.
Ultra crazy not-so-accurate physics. Less size means less distance the electric field might need to displace electrons. Thus less work, less energy expenditure; leading to less electricity cost and reduced heat dissipation since done work is less now.
Just a thought, not backed by scientific work 🤭
Since IBM was able to cramp 18 billion transistors whereas Intel bottleneck at 300 million! This is why Apple Silicons, M1 was way over its competing market in overall perspective when it was launched; The compatibility was the only problem for them which they got around with Rosetta 2 just like when they switched from PowerPC to Intel using Rosetta.
Better manufacturing was the next driving factor for the main outcomes drawn in the paper:-
Better performance
- IBM simply had more power at its core than its competitor Ice Lake chip
Better cost
- How?
Next conclusion from the paper: Less cost!
The paper also concludes that the IBM-option was better cost-wise. I think the author/testers chose the options to juxtapose very well. The paper claims 45% less cost for ownership in 3 years. They highlight the larger portion of the pie is for software, namely WAS hybrid OTC/SWMA and OpenShift. Decoding the shinanigan, it is Websphere Application Server Hybrid edition One Time Charge Software Maintenance Agreement.
The reason is that these services are charged by the number of cores they run on. So, being less core with more power IBM had an unprecedented advantage by comparing with less efficient but more cores alternative. All thanks to the advanced Fabrication process 🙏.
Here is the cost breakdown from the IBM-provided Paper.
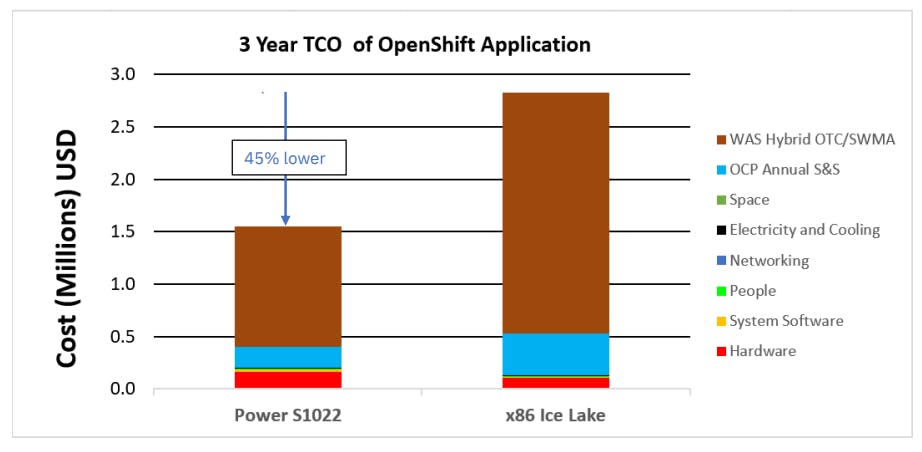
The hidden cost is the red stack, the Hardware. It is obvious IBM Power S1022 costs more than the alternate hardware, but you heard it from IBM it is cheap overall (for 3 years) if you chose this specific tech-stack for the deployment!
That's it? What about the Apple garden 🍎?
Though the EU is pushing Apple to open up the ecosystem I am pro-Apple-Garden from the very beginning. The reason is that it lets the developers know what they are developing for; both hardware and software wise. Leading to a better product experience from the end-user POV.
To Know is To Have Power
The internal knowledge of how things are done despite sharing standard APIs opens up opportunities to further optimize the product. Since Apple designs the hardware and develops the software, Apple developers can eliminate the need for some defensive programming, dynamic environment assumptions and such. Where Windows and generic Linux developers need to support all kinds of devices OEMs offer and worry about diverse configurations and backward compatibility.
The same goes for this paper as well. If you noticed, from the hardware to the virtualization platform is of IBM. And IBM was the original developer of DayTrader as well! The only major third-party product is OpenShift. IBM subject has the advantage of closely built components battle-tested for these specific intentions.
On the other hand, the alternative was glued using components built in isolation by different vendors trying to have a wider market target as much as possible. Not many areas to optimize further, if you say.
So,
Being able to know the CPU(Power10) internals PowerVM can be optimized
Being able to know the other components, Power S1022 could have chosen the motherboard, main memory, power supply and caching memories in favor of their products!
See, vendor lock is not always bad. It is bad when you need to mix and match stuff! The very definition of vendor lock.
Updates
-- intentionally left for future updates --
Epilogue
As the final say, the 🔼 3.6 performance and 🔽 45% cost is because the IBM Power option was mostly since it had better CPU and CPU software along with components that make up IBM Power S1022 DayTradder instance was tightly integrated and well woven.
So next time you go shopping for computers for personal and business use:-
don't look shallow
vendor-specific options might play well together
look at the bigger picture by looking much into the products
let commercial marketing words and go for the specifications and datasheets
This 2 days of research was an eye opener for me and I hope for you as well 🤗. Have a nice day, this is meTheBE signing off 👋.
Thanks for Gerad S S for reviewing 👍